2. semester
Plán pre 2.semester:
- porovnať ARM a Intel
- rozbehať crosskompilaciu z Intelu na ARM
- Prepísať zdroják, tak aby bol prehľadnejší a dali sa do neho jednoduchšie
pridávať rôzne algoritmy na počítanie biquadu. Vytvoriť kostru.
- vypisovanie testov pre rôzne veľkosti bufferov.
- zoptimalizovať výpočet na 1-channel audiu pomocou NEON-u
- zoptimalizovať výpočet na 2-channel interleaved audiu pomocou NEON-u
Zdrojáky:
Zdrojáky
Zmeny
Tento semester som vytvoril hlavnú kostru, do ktorej sa dajú pridávať ďalšie algoritmy. Do tejto
kostry som pridal veci z prvého semestra a plus som ešte pridla ďalšie. Hlavná časť bolo skúsiť SIMD
inštrukcie na ARM-e a porovnať to s Intelom(SSE).
Porovnávané algoritmy:
- obyčajná priamočiara implementácia; v grafoch sú to: 2-ch no SIMD a 1-ch SIMD
- 1-ch a 2-ch verzia s NEON a SSE inštrukcie s podobným algorimom ako tuna
- ADD - tento algoritmus iba pričíta konštantu ku každej hodnote; cieľ tohto je, aby sme vedeli,
že aké je teoretické maximum; verzia so SIMD a bez
- NOP - no-operation - nameraný je iba overhead, ktorý vznikol pri kopírovaní buffera, keď
podhadzujem algoritmu dáta
ARM(NEON)
Pozorovania:
- Na ARM-e sa ukázalo, že algoritmus, ktorý som používal na paralelizáciu dvojkanálového sa moc
neoplatil. Lepšie je dvakrát sekvenčne spustiť sparalelizovaný algoritmus na jednokanálové
audio.
- So SIMD sme dosiahli až 4-krát lepšie výsledky oproti obyčajnej verzii.
- Vyzerá to tak, že pri našom SIMD algoritme nezáleží na veľkosti buffera. Merania boli prevedené na dátach so stále tým istým
objemom. Konkrétne 2^24 bytov, čo je pri 1-ch audiu zhruba 95 sekúnd.
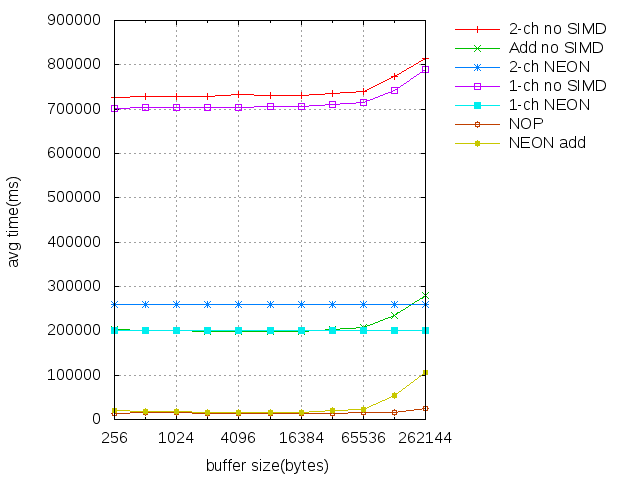 Kompilové s flagmi: -mfloat-abi=softfp -mfpu=neon -g -O3 -std=gnu++0x -Wno-psabi
Crosskompiloval som to na Intely s gcc 4.4
Kompilové s flagmi: -mfloat-abi=softfp -mfpu=neon -g -O3 -std=gnu++0x -Wno-psabi
Crosskompiloval som to na Intely s gcc 4.4
Intel(SSE)
Pozorovania:
- Pri Intel architektúre nám to dopadlo naopak. Viac sa nám oplatí použiť 2-ch sparalelizovaný
algoritmus ako dvakrát spustiť 1-ch verziu.
- Už sme nedostali také závratné zrýchlenie pomocou SIMD
ako pri ARM-e. Zrýchlili sme to zhruba 2-krát. ARM je load/store architektúra, takže predpokladám,
že spomalenie pri obyčajnej verzii na ARM dosť spôsobovali loady a story 4-bytov. Pri NEON-e sme
vedeli urobiť load/store až 16-bytov naraz. Gcc absolutne nevedelo ani takúto jednoduchú operáciu
zvektorizovať. Pri SSE už vidíme, že vo verzii "Add no SIMD" kompilátor využil SSE inštrukcie.
Objdump to potvrdil.
- Pri Intely sa merania trocha viac hýbali s veľkosťou buffera. Pri prechode zo 16K na 32K môžeme
vidieť skok v rýchlosti v každom algoritme. 32K je veľkosť L1 cache. Tentokrát som to musel testovať
s 2^28 bytami, lebo Intel procesor, ktorý som mal k dispozícii bol rýchlejši ako ARM. Inak by nebolo
vidieť tie merania poriadne.
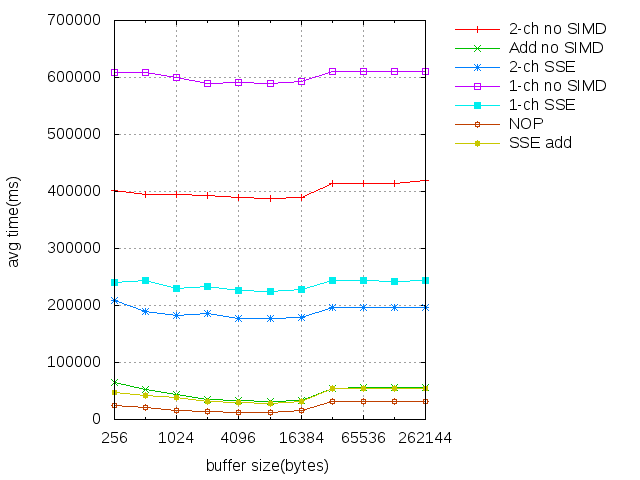 Kompilované s flagmi: -mssse3 -std=c++11 -g -O3
Kompilované s flagmi: -mssse3 -std=c++11 -g -O3
Použitý hardware
ARM
Processor : ARMv7 Processor rev 2 (v7l)
BogoMIPS : 996.14
Features : swp half thumb fastmult vfp edsp thumbee neon vfpv3
CPU implementer : 0x41
CPU architecture: 7
CPU variant : 0x3
CPU part : 0xc08
CPU revision : 2
Hardware : OMAP3 Beagle Board
Revision : 0020
Serial : 0000000000000000
Intel
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 15
model name : Intel(R) Core(TM)2 Duo CPU T7100 @ 1.80GHz
stepping : 13
microcode : 0xa1
cpu MHz : 1801.000
cache size : 2048 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 2
apicid : 0
initial apicid : 0
fdiv_bug : no
f00f_bug : no
coma_bug : no
fpu : yes
fpu_exception : yes
cpuid level : 10
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush
dts acpi mmx fxsr sse sse2 ss ht tm pbe nx lm constant_tsc arch_perfmon pebs bts aperfmperf pni
dtes64 monitor ds_cpl vmx est tm2 ssse3 cx16 xtpr pdcm lahf_lm ida dtherm tpr_shadow vnmi
flexpriority
bogomips : 3591.04
clflush size : 64
cache_alignment : 64
address sizes : 36 bits physical, 48 bits virtual
power management:
processor : 1
vendor_id : GenuineIntel
cpu family : 6
model : 15
model name : Intel(R) Core(TM)2 Duo CPU T7100 @ 1.80GHz
stepping : 13
microcode : 0xa1
cpu MHz : 800.000
cache size : 2048 KB
physical id : 0
siblings : 2
core id : 1
cpu cores : 2
apicid : 1
initial apicid : 1
fdiv_bug : no
f00f_bug : no
coma_bug : no
fpu : yes
fpu_exception : yes
cpuid level : 10
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush
dts acpi mmx fxsr sse sse2 ss ht tm pbe nx lm constant_tsc arch_perfmon pebs bts aperfmperf pni
dtes64 monitor ds_cpl vmx est tm2 ssse3 cx16 xtpr pdcm lahf_lm ida dtherm tpr_shadow vnmi
flexpriority
bogomips : 3591.04
clflush size : 64
cache_alignment : 64
address sizes : 36 bits physical, 48 bits virtual
power management: